概要
「みを(miwo)」アプリは、くずし字資料を読みたい人を手助けするアプリです。くずし字資料をカメラで写真撮影し、認識ボタンを押すだけで、AIがくずし字を現代文字に変換してくれます。
ROIS-DS人文学オープンデータ共同利用センター(CODH)では、画像に含まれるくずし字を現代の文字に変換する(翻刻する)機能を備えたAIくずし字認識技術を開発しました。この技術が誰でも気軽に使えることを目指して開発したのが、AIくずし字認識スマホアプリ「みを(miwo)」です。
「みを」は『源氏物語』第14帖「みをつくし」にちなんだ名前です。「みをつくし」が人々の水先案内となるように、「みを」アプリがくずし字資料の海を旅する案内となることを目指しています。
主な機能
- カメラで撮影した画像や、ネットからダウンロードした画像を対象に、くずし字を認識して現代の文字に変換する(翻刻する)ことができます。
- 認識した文字を画像上に表示できます。また文字の位置を表す四角形を表示することもできます。
- 認識結果が正しくない場合、文字を修正することができます。
- 認識結果をテキストとして出力し、コピーして他のアプリで使うことができます。
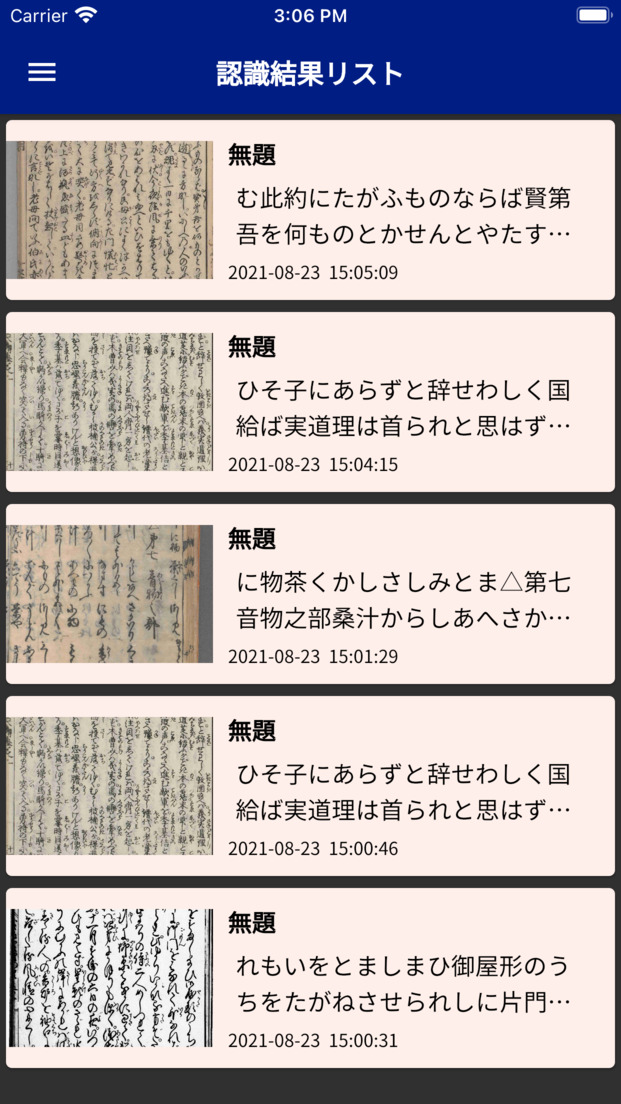
- 認識結果をアプリ内に保存し、後で呼び出すことができます。
- CODHのくずし字データセットと連携し、アプリ内からくずし字の用例を検索できます。

|

|
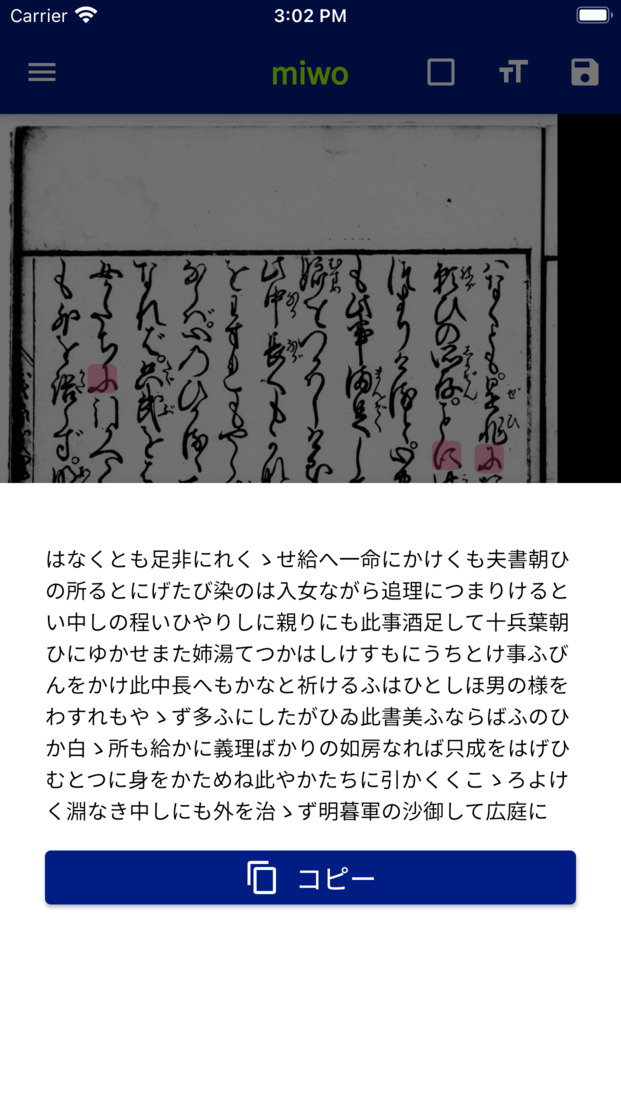
|
|
| くずし字認識結果の文字表示と書籍画像との比較スライダー | 変体仮名の字母表示とくずし字データセットへのリンク | 認識結果のテキスト表示とコピーボタン | 認識結果の保存と読み出し |
特徴
「みを」アプリの開発にあたっては、スマートフォンやタブレット上でAIくずし字認識を活用するにはどんなユーザインタフェースが望ましいかを検討しました。その際に意識したことは、AIによるくずし字認識は決して完璧にはならないが、それでも役に立つという点です。
まず初学者、あるいは一般のくずし字が読めない日本人にとっては、文書にどんな文字が書いてあるかがわかるだけでも、内容が推測できるようになるという利点があります。この場合、そもそも人間の認識精度があまり高くないため、AIの精度は人間の精度を上回ることが多いと言えます。したがって、このタイプのユーザにとって、「みを」は役に立つアプリとなるはずです。
一方、くずし字が読める上級者や専門家にとっては、AIの精度は人間の精度に達しないことも多いため、アプリだけで何か新しいことがわかるわけではありません。しかし資料調査の現場においては、短い時間で多くの資料の内容を把握するために、スピードが重視される場合があります。いくらくずし字が読めるとはいっても、アプリがくずし字を現代の文字に変換してくれた方が、やはり読みやすくなることは確かです。したがって、1枚あたり数秒でくずし字を翻刻してくれる「みを」は、こうした現場でも役に立つはずです。
以上の想定を踏まえ、以下のような機能をアプリに組み込みました。
まず専門家に向けて、資料調査の現場での利用を想定し、AIによる認識結果の修正機能や保存機能、テキスト出力機能などを開発しました。テキスト出力結果をコピーし、他のアプリにデータを持ち出すこともできます。
次にくずし字を読みたい初学者のくずし字学習を手助けするため、くずし字認識結果の表示方法を工夫しました。
- AIの認識結果に対応する元画像の領域を切り抜き、認識結果と字形が比較できるようにしました。
- 文字の領域を示す四角形を画像に重ねて表示することにより、続けて書かれるくずし字(連綿体)の切れ目がわかるようにしました。
- CODHのくずし字データセットと連携し、認識結果に疑問を抱いた時には、くずし字の用例を確認できるようにしました。
開発
現代のアプリ開発において、より多くの人々にアプリを届けるためには、AndroidとiOSという二大プラットフォームにいかに対応するかが重要な課題です。両者は開発言語や開発環境が異なるため、大手企業などでは同一機能を備えた2つのアプリを並行して開発する場合もありますが、我々のような少人数のチームではそうした体制は現実的ではありません。
そこで我々は、Googleが推進するFlutterを活用したクロスプラットフォーム開発により、この問題を解決することにしました。Flutterは単一のソースコードからAndroidとiOSに対応したアプリが作成できるため、これによりAndroidとiOSのスマートフォンやタブレットに幅広く対応することができました。
注意事項
- 「みを」アプリのAIは、江戸時代の版本から集めたくずし字データを学習しているため、江戸時代の版本に対する精度が比較的高めとなりますが、他の時代の資料や、写本、古文書などでは、精度が低下する可能性があります。
- シミ、虫食い、紙の柄などの資料状態により、また照明、影などの撮影環境により、精度が低下することがあります。
- 石碑や看板などに書かれたくずし字は、現在のところ認識できません。
- バージョン1.0で保留していた合略仮名「こと」の問題については、Unicodeでの扱いが決まっていないため、バージョン1.1から利用するRURIでは、片假名の「ヿ」で代用することにしました。そして「ヿ」を含むデータセットを独自に構築し、RURIに学習させることで、「こと」の文字が認識できるようになりました。なおこの文字は現在のくずし字データセットには含まれていませんが、近日中に拡大版のくずし字データセットを公開する予定です。
また、利用規約でも明記しておりますように、くずし字認識結果には誤りが含まれることがありますので、ユーザご自身でご確認ください。また本センターは、くずし字認識の誤りに関するお問い合わせは受け付けておりません。誤りのない翻刻をご希望の場合は、企業や個人が提供する翻刻サービスなどをご利用下さい。
バージョン
バージョン1.1 (2022-10-26)
新規開発したAIくずし字認識システムRURI(瑠璃)を利用します。従来のAIくずし字認識モデルと比較して、RURIにはAI物体検出技術をくずし字認識に最適化するための工夫が加えられており、文字背景の色や模様が複雑な場合でも精度が向上しています。また国文学研究資料館が作成しCODHが公開する、100万文字以上の「日本古典籍くずし字データセット」を独自に強化することで、これまで認識できなかった文字が新たに認識できるようになりました(参考:プレスリリース)。
バージョン1.0 (2021-08-30)
AIくずし字認識については、CODHが開発したくずし字認識モデルKuroNet、およびKaggleくずし字認識コンペで1位となったtascj氏が開発したくずし字認識モデルを利用します。またこれらのAIモデルの学習には、国文学研究資料館が作成しCODHが公開する日本古典籍くずし字データセットを活用しました。