miwo: App for AI Kuzushiji Recognition
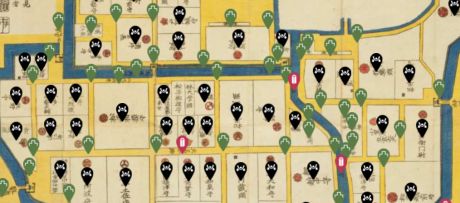
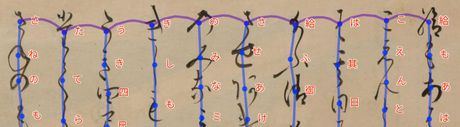
I want to read the kuzushiji material! But I can't read them! "miwo" is an app that helps such people. Just take a picture of the material with the camera, press a button, and the AI will convert the kuzushiji into modern characters. Welcome to the world of kuzushiji documents.

KuroNet Kuzushiji Recognition
Multi-character (one-page) Kuzushiji recognition service is developed using AI (machine learning). A service for IIIF (International Image Interoperability Framework) images is also released to transcribe kuzushiji images across the world.

soan
Soan is a service that allows users to input modern Japanese text to generate and share kuzushiji images. The software and service enables anyone to digitally typeset old movable type (kokatsuji) from "Sagabon," which are one of the most beautiful books in the history of Japanese publishing.

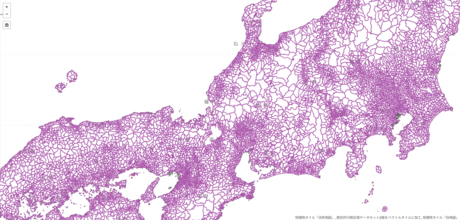
Historical Big Data
Historical big data is a project for the seamless analysis of environment and society from the past to the present by structuring various records written by humans.

Edo+150 Projects
On November 9, 1867, the restoration of imperial rule symbolized the end of Edo Period. 150 years have passed since then, and now is the time to revive the information space of Edo, using open data about the 260 years of Edo period, and taking advantage of the state-of-the-art technologysuch as artificial intelligence (AI).

edomi - Data Portal for the Historical Edo
To create a vantage point for the various data about the Edo as a city or the Edo as a period, we create a data portal for structuring and integrating data on the historical Edo in response to the needs of present people.

Bukan Complete Collection
The project aims at analyzing comprehensively the collection of "Bukan" books, which is the best seller through the 200 years of Edo period, and constructing core information platform about Edo period in terms of human and geospatial information about Daimyo (lords) and Shogunate government.

Image Collation Service for Differential Reading
Read two images, overlay them, and emphasize the difference. A service useful for "spot the difference" on images with partial difference, such as the collation of images between different versions of woodblock-printed books.

GeoLOD
We develop a platform for assigning identifiers to place names and sharing gazetteers.

GeoNLP
By integrating geographic information science (GIS) and natural language processing (NLP), we develop a geo-tagging system for automatically transforming text to maps.

North China Railway Archive
A research database on North China Railway Company by linking company's promotional stock photographs with its transportation network, and studying the activities of the company from the theme and location of photographs.

Memorygraph
Memorygraph is a camera app that supports same-composition photography. We use now-and-then photography, before-and-after photography, fixed-point photography, and pilgrimage photography for cultural heritage, tourism, and recovery from disasters.

Digital Silk Road
Digital humanities research project about creating digital archives of cultural heritage based on collaboration between informatics and humanities.