
Dataset of Pre-Modern Japanese Text
Pre-Modern Japanese Text, owned by National Institute of Japanese Literature, consists of image and text data and was released as open data. Some books also have summary, transcription, and tagging data.
Pre-Modern Japanese Text, owned by National Institute of Japanese Literature, consists of image and text data and was released as open data. Some books also have summary, transcription, and tagging data.

Cooking books in the Edo period, provided from Dataset of Pre-Modern Japanese Text, were curated for creating recipe datasets through the process of transcription, translation to modern Japanese, and structuring into the recipe format.

As a by-product of transcription for the Dataset of Pre-Modern Japanese Text (PMJT), shapes and coordinates of old Japanese characters (Kuzushiji) were compiled to create another dataset for training to make machines and humans smarter.

Adapted from Kuzushiji Dataset, KMNIST dataset is a drop-in replacement for MNIST dataset. We provide three types of datasets, namely Kuzushiji-MNIST、Kuzushiji-49、Kuzushiji-Kanji, for different purposes.

The project aims at making research infrastructure for art history research by collecting facial expressions for style compartive study from Japanese Emaki (illustrated scroll), or potentially from work of art across the globe.

Introduce methodologies of machine learning and data science to Ukiyo-e research, and construct a new digital research infrastructure on Japanese culture.

Edo shopping guide is derived from "Edo Kaimono Hitori Annai" published in the Edo Period by cropping advertisement from books and adding the name of merchants with their business, address and the logo to create a visual database of merchants in and around the city of Edo.

Edo Sightseeing Guide is derived from tourism guides published in the Edo Period by cropping illustration from books and adding names, keywords and geographic information to create a visual tourism guide of Edo.
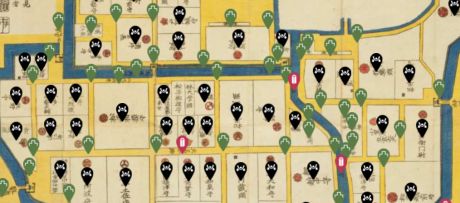
Edo Maps Beta is a project to construct geographic information infrastructure for the urban space of Edo City by extracting place names from Edo Kiriezu and econstructing information from old documents from the Edo Period.
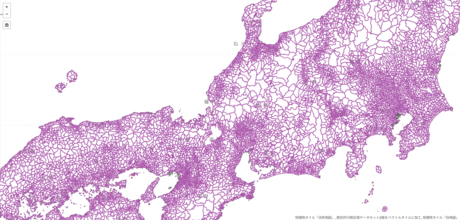
Geoshape repository is a data repository for sharing the geographic shape of a geographic entity. It includes "Historical Municipal Boundaries Dataset Beta Version" about the historical change of municipal boundaries since 1920 and "Village Boundaries Dataset" of 2015.

Seal Script Dataset is a machine learning-friendly dataset of "Tensho" character images cropped from old dictionaries of characters from Japan and China to be used for the interpretation of seals.

Based on the results of digitization of magazines published in the early to mid-Meiji period (modern magazines), we release machine learning datasets for OCR and develop OCR software (Kindai-OCR).