
日本古典籍データセット
歴史的典籍NW事業においてデジタル化された古典籍のうち、主に国文研所蔵本を対象に、画像データと書誌データをセットで公開しています。さらに一部の古典籍には作品紹介や翻刻テキストデータ、タグ情報なども付与しています。
歴史的典籍NW事業においてデジタル化された古典籍のうち、主に国文研所蔵本を対象に、画像データと書誌データをセットで公開しています。さらに一部の古典籍には作品紹介や翻刻テキストデータ、タグ情報なども付与しています。

日本古典籍データセットに含まれる江戸の料理本を対象に、江戸の料理文化に関するデータとして、翻刻・現代語訳・レシピ化という作業を加えたレシピデータを提供します。

日本古典籍データセットで公開するデジタル化された古典籍を対象に、翻刻テキストの制作過程で生まれるくずし字の切り出された字形と座標情報などを、機械や人間を賢くするための学習データとして提供します。

日本古典籍くずし字データセットを元に、機械学習研究で著名なMNISTデータセット互換のくずし字データセットKMNISTを作成しました。目的に応じて、Kuzushiji-MNIST、Kuzushiji-49、Kuzushiji-Kanjiの3種類のデータセットをご利用下さい。

篆書字体データセットは、印文解読に有用と思われる和漢の字書・字彙類から切り出した篆書字体画像を、機械学習に利用しやすい形式で提供します。

古活字データセットは、「嵯峨本」などに使われた古活字を、古活字版の情報学的解析に基づき推定して作成したものです。

日本の絵巻物を中心として古今東西の美術作品から顔貌を切り取って収集し、顔の描き方を比較検討する、美術史研究(特に様式研究)のための研究基盤を構築するプロジェクトです。

浮世絵研究に機械学習やデータサイエンスの方法論を適用し、日本文化に関する新しいデジタル研究基盤を構築します。

江戸買物案内は、江戸時代に出版された『江戸買物独案内』から広告版面を切り抜くとともに、商人名や職種、居所(住所)、屋号紋などを抽出することで、江戸を中心とする商人に関するビジュアルな商業広告データベースとして構築したものです。

江戸観光案内は、江戸時代に出版された観光ガイドブックから挿絵を収集するとともに、名称やキーワードを付与することで、江戸を中心とする観光に関するビジュアルな名所挿絵データベースとして構築したものです。
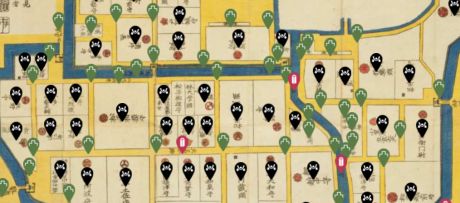
江戸マップは、国立国会図書館が公開する古地図「江戸切絵図」から地名を抽出して地名データベース化するとともに、現代の地図や情報とも統合することで、歴史ビッグデータや歴史GISの研究や江戸都市空間の地理情報基盤の構築に活用します。
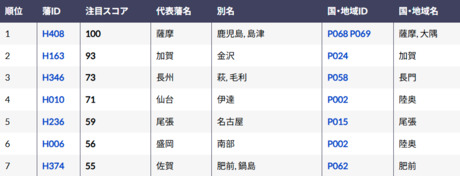
藩IDデータセットは、江戸・明治時代の藩に識別子(ID)を付与するとともに、藩名と別名も定義したデータセットです。また藩に関する独自の情報として、研究論文数に基づく「注目スコア」を追加しています。さらに国・地域IDデータセットも新たに作成し、藩と国を識別子で結合しました。
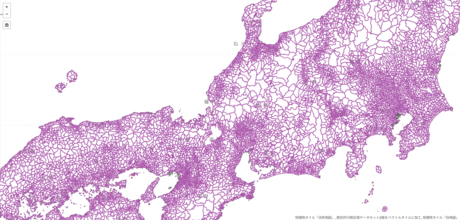
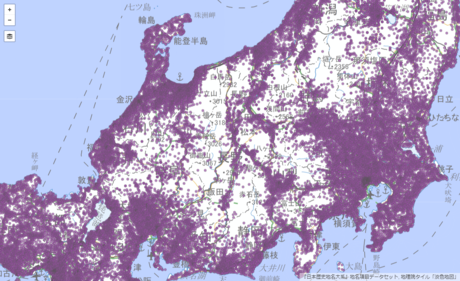
歴史的に存在した市区町村に識別子を付与し、そこに市区町村境界の歴史的変遷を紐づけたデータセットです。1889年の市制・町村制以降の市区町村を対象とし、市区町村境界の変遷をウェブ地図上に可視化する「アニメーション表示可能な歴史地図」も提供します。
ジャパンナレッジで公開する平凡社刊行の『日本歴史地名大系』(全50巻)の地名項目と関連情報をまとめたデータセットです。
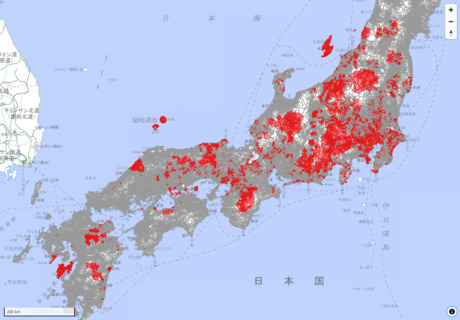
幕末期(慶応年間頃)近世村の領域データと点データ(作成:本田謙一氏)を加工したデータセットです。石高については、旧高旧領取調帳データベース(国立歴史民俗博物館)を参照しています。

明治初期から中期にかけて出版された雑誌(近代雑誌)のデジタル化の成果をもとに、OCR学習用データセットの公開やOCRソフトウェア(Kindai-OCR)の開発などを進めます。
オープンデータ化したデータセットの利活用を促進するために、以下のような試みを行っています。
国文学研究資料館と共同して、LOD Challenge 2016にデータ提供パートナーとして参加しています。 以下はコンテストへの期待です。
日本古典籍にはかつての日本文化に関する情報や知恵が満載です。しかし、その内容を現代の我々が利用することは決して簡単ではありません。どうしたらそれを活用できるでしょうか。また、どんな場面でどんなデータが使えるようになると嬉しいでしょうか。具体的なシナリオを思い浮かべながら、アイデアを自由に広げて下さい。